트리 구조의 예시로는 월드컵 본선 대진표, 회사나 학교의 조직도, 인터넷 상점의 상품 분류 기준등
그러나 사실 트리는 이 외의 용도로 더 많이 사용되는데,
실제 계층 관계가 없는 자료 들을 트리로 표현해서 같은 연산을 더 빠르게 할 수 있는 경우가 많습니다.
비 선형구조 의 자료구조이다.
트리의 구성요소(정의와 용어)
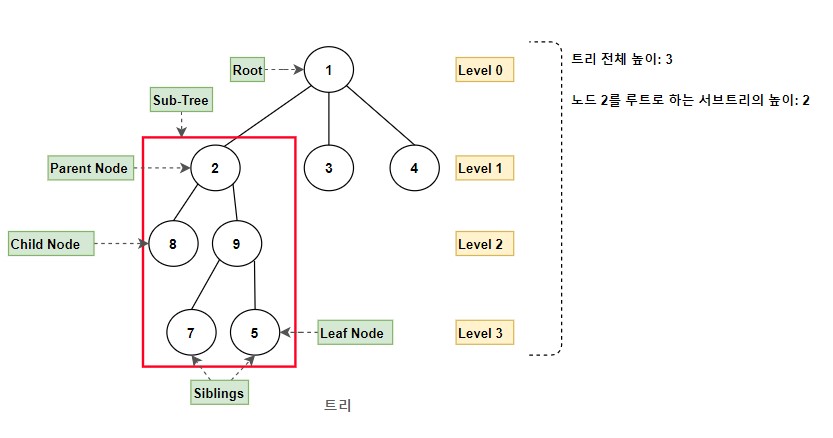
자료가 저장된 노드(node)
노드와 노드를 연결하는 간선(edge)
노드 간에는 상/하위 관계가 있다.
두 노드가 연결되었을 때 한 노드는 좀더 상위, 다른 노드는 좀더 하위에 있어야 한다.
노드에서 상위 노드를 부모(parent) 라고 한다.
하위 노드는 자식(child) 노드라고 한다.
부모 노드가 같은 두 노드는 형제(sibling) 노드라고 한다.
부모 노드와 그의 부모들을 통틀어 선조(ancestor) 라고 한다.
자식 노드와 그의 자식들을 통들어 자손(descendant) 라고 한다.
트리에서 한 노드는 여러 개의 자식을 가질 수 있어도 부모는 하나만 가질 수 있다.
트리에서 최상위 노드, 다른 모든 노드들을 자손으로 갖는 노드를 트리의 뿌리 혹은 루트(root) 라고 한다. 반대로 자식이 하나도 없는 노드들을 트리의 잎 노드 혹은 리프(leaf) 라고 한다.
트리와 노드의 속성
루트에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수를 해당 노드의 깊이(depth) 라고 한다.
가장 깊숙히 있는 노드의 길이를 해당 트리의 높이(height) 라고 한다.
트리의 재귀적 속성
트리가 유용하게 사용되는 큰 이유 중 하나는 트리가 재귀적인 성질을 갖고 있기 때문이다. 트리에서 한 노드와 그의 자손들을 모두 모으면 그들도 하나의 트리가 된다.
어떤 노드 t와 그 자손들로 구성된 트리를 ‘t를 루트로 하는 서브트리(subtree)’ 라고한다.
트리는 서브트리들의 집합이라고 말할 수 있다.
//==트리의 노드를 표현하는 객체의 구현==//structNode{stringlabel// 저장할 자료 (문자열일 필요는 없다)Node*parent;// 부모 노드를 가리키는 포인터vector<Node*>child;// 자손 노드들을 가리키는 포인터의 배열};
트리의 순회
트리의 경우 선형으로 구성된 배열과 달리 트리는 그 구조가 일정하지 않기 때문에 포함된 모든 자료들을 순회하기가 쉬운 일이 아닙니다. 이와 같은 일을 쉽게 하기 위해서는 트리의 재귀적 속성 을 이용해야 합니다.
//==트리를 순회하며 모든 노드에 포함된 값을 출력==//voidprintLabels(Node*root){// 루트에 저장된 값 출력cout<<root->lable<<"\n";// 각 자손들을 루트로 하는 서브트리에 포함된 값들을 재귀적으로 출력for(inti=0;i<root->child.size();++i){printLabels(root->child[i]);}}
//==root를 루트로 하는 트리의 높이를 구하기==//intheight(Node*root){inth=0;for(inti=0;i<root->children.size();++i){h=max(h,1+height(root->children[i]));}returnh;}
트리 구현(C++)
#include<bits/stdc++.h>usingnamespacestd;structNode{intdata;Node*parent;vector<Node*>child;Node(intdata){this->data=data;this->parent=this;}};structTree{Node*root;Tree(){root=NULL;}//루트 노드 생성voidcreateNode(intdata){if(root==NULL){root=newNode(data);}}//자식노드 생성voidaddChildNode(intparent,intdata){if(root==NULL){root=newNode(parent);Node*childNode=newNode(data);root->child.push_back(childNode);childNode->parent=root;}else{searchNode(root,parent,data);}}//노드 탐색voidsearchNode(Node*root,intparent,intdata){if(root==NULL)return;if(root->data==parent){Node*childNode=newNode(data);root->child.push_back(childNode);childNode->parent=root;}else{for(inti=0;i<root->child.size();i++){searchNode(root->child[i],parent,data);}}}//트리 출력voidprintTree(Node*root){if(root==NULL){cout<<"노드가 존재하지 않습니다.\n";return;}else{cout<<root->data<<"";for(inti=0;i<root->child.size();i++){printTree(root->child[i]);}}}//==root를 루트로 하는 트리의 높이를 구하기==//intheight(Node*root){inth=0;for(inti=0;i<root->child.size();++i){h=max(h,1+height(root->child[i]));}returnh;}};intmain(void){Treetree;tree.createNode(1);tree.addChildNode(1,2);tree.addChildNode(1,3);tree.addChildNode(1,4);tree.addChildNode(2,8);tree.addChildNode(2,9);tree.addChildNode(9,7);tree.addChildNode(9,5);tree.printTree(tree.root);//1 2 8 9 7 5 3 4cout<<"\n"<<tree.height(tree.root);//3}
시간 복잡도
트리에 n개의 노드가 있다고 하면 이들을 모두 순회하기 위해서는 O(n) 의 시간이 들어야 정상이다.